Sommaire.
-
Le code.
-
Image.
-
Conclusion & téléchargement
Introduction.
Le but de ce projet fut de nous sensibiliser avec les techniques d'encodage et de décodage de données en utilisant des codes détecteurs et correcteurs d'erreurs. Le langage n'était pas fixe et notre choix s'est porte sur l'assembleur. En effet, nous étions auparavant assez a l'aise an C/C++, java et matlab, aussi était-ce une bonne occasion de se plonger dans un nouveau langage. De plus, l'assembleur permet une approche plus " matérielle " des codes correcteurs d'erreurs : en effet, les matériels qui utilisent ce genre de codes (modems, satellites?c) sont généralement composes de microprocesseurs, lesquels sont programmes en assembleur. Bien que l'assembleur pc (CISC) soit sensiblement différent des codes assembleurs " embarques " (la plupart du temps, architecture RISC), l'expérience de ce projet sera sans doute appréciable si l'un de nous doit un jour travailler sur des codes correcteurs embarqués.
Une autre liberté que nous avons prise fut le code a utiliser. Si le sujet tournait autour d'un code de Hamming 7,4, nous avons préféré apprendre comment construire un code a partir de rien, et nous étions aussi curieux de savoir comment les codes corrigeant plusieurs erreurs fonctionnaient. De plus, avec un code (7,4), 2 bits sur 16 sont perdus, alors qu'ils pourraient être utilises pour la correction.
Enfin, nous avons étendu le sujet en lui donnant une dimension graphique. S'il est un peu plus difficile de programmer de l'image en assembleur plutôt que dans d'autres langages de plus haut niveau, il aurait été dommage que des étudiants en dernière année d'informatique ne sachent pas s'acquitter de cette tache.
Le code.
Choix du code.
Taille des mots d'informations.
La taille des mots d'informations va directement influencer le choix d'un code : s'il est possible de décomposer un mot d'information en plusieurs mots de taille inférieure, l'inverse est plus difficile. De plus, si le code choisit permet de traiter les mots d'information sans avoir a les modifier, cela éviterait un traitement supplémentaire. La question a se poser est donc quelle est la taille de nos mots d'informations. Pour la partie image, il est facile de répondre a la question : le mode graphique utilise permet 320x200 pixels et 256 couleurs palettisées Ce qui signifie que chaque pixel est compris entre 0 et 255. Chaque pixel est codé sur un octet.
S'il est vrai que le code ASCII original proposait 127 caractères différents, soit 7 bits pour le caractère, plus 1 de parité, ce code était avant tout destine aux US et angleterre. La norme ISO-8859-1, plus connue sous le nom d'ISO-LATIN-1 (ASCII étendu) a rapidement été adoptée, car permettant les caractères avec accents, tréma, ou plus concrètement la plupart des caractères latins dont le code ASCII original était dépourvu. C'est ce code qui est mis en place sur la plupart des OS actuels, et utilise 8 bits pour coder un caractère (0-127 : codes ASCII originaux, 127-255 : caractères spéciaux : é,à,ç). Il n'y a donc pas de bit de parité sur le code ASCII étendu
Nous constatons que les caractères, tout comme les pixels, sont codes sur un octet. Un même code permettra donc de faire les deux parties de ce projet.
Pourquoi pas le code de Hamming(7,4)
Après avoir étudié le code de Hamming en TD et en cours de TL51, mais aussi a l'IUT, et bien que nous lui concédions nombres avantages, nous avons décidé de ne pas l'utiliser : en effet, si celui-ci peut corriger très rapidement une erreur (le syndrome étant directement le numéro du bit erroné), il ne corrige qu'une erreur. Sachant que pour des raisons évidemment pratiques nous utilisons 2 octets pour coder un mot d'information, il restait deux bits inutilisés avec un code de Hamming (sur 2 octets de code, 8 bits d'information et 6 bits de contrôle). De la nous est venue l'idée d'utiliser ces deux bits afin de permettre une détection et correction plus efficace. De plus, nous n'avions jamais vu comment corriger plus d'une erreur, et nous souhaitions en savoir un peu plus sur ce sujet. Enfin, d'un point de vue mathématique, nous étions assez curieux de savoir comment mettre au point un code.
Pour résumer, nous n'avons pas utilise le code de Hamming (7,4) du fait que nous étions désireux d'en savoir plus sur l'élaboration de codes linéaires. Nous avons donc mis en place notre propre code (16,8) qui n'a pas la prétention d'être trop efficace, mais qui aura eut le mérite de nous avoir fait " voir du pays " dans le domaine des codes détecteurs et correcteurs d'erreurs.
Définition du code.
Étant donne que nous travaillons en assembleur, il est crucial que notre code soit le plus facile possible tant a utiliser qu'à mettre en place. Nous devons coder 8 bits sur 16. Nous avons donc décidé d'utiliser un code systématique, les 8 bits de poids fort Étant les bits de contrôles (nombres d'instructions assembleurs travaillent sur les 8 bits faibles des registres 16 bits, ce qui rend plus aise l'extraction de données du code (par exemple stosb met dans l'adresse pointée par le couple es :[di] la valeur contenue dans al, qui est l'octet de poids faible du registre ax (16 bits)).
Une partie de notre matrice de codage est donc définie, puisqu'il s'agit de l'identité Le plus dur est donc de trouver la deuxième partie de notre matrice (cette deuxième partie Étant une matrice 8x8, puisque nous travaillons avec un code (16,8). Sachant qu'il serait plus simple de calculer cette matrice en assembleur plutôt que de la stocker, nous avons pense a faire une sorte de matrice cyclique, cependant, nous ne pouvons parler de code cyclique puisque la matrice de codage dans sa globalité n'est, elle, pas cyclique.
Nous souhaitons corriger 2 erreurs. La distance de Hamming doit être au minimum de 5. Il fallait donc au moins 4 bits a 1 dans notre matrice " N ". Le problème Étant de trouver la plus grande distance possible, tout en conservant des vecteurs linéairement indépendants. Par tâtonnement, nous décidâmes de partir sur le mot binaire 1011 0011 et a partir de rotation, d'en construire la matrice, ce qui nous donna :
[ ID ] [ N ]
1000 0000 1000 1011
0100 0000 1100 0101
0010 0000 1110 0010
0001 0000 0111 0001
0000 1000 1011 1000
0000 0100? 0101 1100
0000 0010 0010 1110
0000 0001 0001 0111
Le principal avantage est que la matrice N est doublement cyclique (il est possible de générer chaque ligne en décalant la précédente vers la droite, mais aussi chaque colonne en décalant la précédente vers le bas (nous utilisons cette propriété). Mais avant de pouvoir utiliser ce code, il faut pouvoir affirmer qu'il est linéaire.
Un code est linéaire. si pour v appartenant a {0,1}^8,? v.C=0?? =>?? v=0
Soit donc v=(a,b,c,d,e,f,g,h)
D'après l'égalité v.C=0, si l'on ne tient pas compte de la partie identité (les vecteurs Étant évidement indépendants.), la deuxième partie du mot de code est définit comme suit :
1) a+b+c+f+g? = 0
2) b+c+d+g+h = 0
3) a+c+d+e+h = 0
4) a+b+d+e+f ?= 0
5) b+c+e+f+g? = 0
6) c+d+f+g+h? = 0
7) a+d+e+g+h = 0
8) a+b+e+f+h? = 0
1) + 2) => b+c+g=a+f=d+h
1) + 3) => a+c=b+f+g=d+e+h=a+f+e=b+c+g+e?? => c=f+e
+5) => b+c+e+f+g=0 => b=g
+6) => c+d+f+g+h=0 => f+e+d+f+g+h=0 => e+b+c+g+g=0 => e+b+f+e=0 => b=f=g
+8) => a+b+e+f+h=0 => a+e+h=0
+4) => a+c+d+e+h=0 => e+h+c+d+e+h=0 => c=d
+7) => a+d+e+g+h=0 => a+b+c+g+e+g=0 => a+b+c+e=0 =>h+b+c=0 =>h+b+d=0
Donc a=b=c=d=e=f=g=h=0. On a bien v.C=0=>v=0 (on en était déjà sur étant donné le caractère systématique du code, mais on vient en plus de vérifier que N est aussi une base.
Nous somme maintenant surs que notre code est linéaire, mais quelle est sa distance de Hamming ? sachant qu'il est assez difficile de la déterminer rapidement " a la main ", nous avons mis au point une fonction de calcul de distance de Hamming. Sachant que, pour un code linéaire., la distance de Hamming est égale au plus petit poids d'un mot, il suffit juste de générer tous les mots de code et de mémoriser celui dont le poids est le plus faible.
La fonction est la suivante :
;=====================================
; Fonction CheckHammingDist
; Paramètres:
; al=1ere colonne de la Matrice
; Retour:
; al:distance de Hamming du code
;
;=====================================
CheckHammingDist proc
mov bl, 00FFh
mov bh, al
mov cx, 256d
deb_chd:
dec cx
jz fin_chd
mov ax, cx
push cx
push bx
mov ah, bh
call EncodeByte
call GetWordWeight
pop bx
pop cx
cmp bl, al
jbe deb_chd
mov bl, al
jmp deb_chd
fin_chd:
mov al, bl
ret
CheckHammingDist endp
Cette fonction se contente de parcourir les mots d'info de 0 a 255 et de générer leur mot de code correspondant. Ensuite elle compare le poids de ce mot avec le plus petit poids déjà découvert, si ce poids est plus petit, alors le minimum enregistre est mis a jour.
Mais a la suite de l'exécution de cette fonction, nous eumes la désagréable surprise de constater que notre code avait une distance de Hamming de 4, ce qui ne nous permettais pas de corriger 2 erreurs. Après une petite phase de déprime, l'idée suivant nous vint : puisque nous avions un moyen de vérifier la distance de Hamming? de n'importe quelle code dont la matrice 8x16 serait systématique (et dont la partie code est cyclique), pourquoi ne pas écrire une fonction pour trouver le meilleur code, suivant le modèle de la fonction pour trouver la distance de Hamming ? Son principe est des plus simple : sachant que la première moitié de la matrice est constance, et que la deuxième est cyclique, il n'y a que 255 matrices différentes. La fonction appelle donc la fonction " CheckHammingDist " sur chacune de ces possibilités, et retient la meilleure (celle dont la distance de Hamming est la plus grande).
Vous devez penser que manipuler 255 matrices de 8 par 16 est énorme, mais du fait que nous programmons en assembleur, simplifier l'information n'est pas pour nous une option mais une obligation.
Plus l'information est grande, plus il y a de traitement, et l'assembleur rends les traitements vraiment pénibles a programmer. De ce fait, qu'est ce qu'une matrice de code, dans notre cas ? une matrice 8x8 d'identité jointe a une matrice 8x8 de code. Nous pouvons d'ores et déjà supprimer la partie identité, puisque nous savons que toutes nos matrices auront cette forme.
Et la partie code est cyclique, ce qui signifie que chaque ligne est une rotation de la ligne précédente Donc chaque ligne peut être déduite de la 1ere. Pour représenter nos matrices 8x16, nous n'utilisons donc qu'un octet, qui se révèle être la première ligne de la matrice de code. Donc les quantités d'informations échangées dans les traitements pour trouver la meilleur matrice ou la distance de Hamming d'un code sont nettement plus réduites.
De ce fait, nous avons donc mis au point une fonction permettant de générer notre matrice de code. (et nous affichons cette matrice en début de notre programme).
Implémentation.
Grâce a nos fonctions, nous pouvons trouver un code de distance = 5. Nous sommes donc en mesure de corriger 2 erreurs. Mais comment faire ? Après quelques heures de recherches, nous sommes arrives a la conclusion que l'utilisation d'une table de syndromes était nécessaire. Pour corriger nos mots de code, il suffit d'en calculer le syndrome. Si celui-ci égal 0, il n'y a pas d'erreur. Dans le cas contraire, il convient de parcourir cette table de syndrome et de trouver le syndrome du mot. Une fois celui-ci trouve, il ne reste plus qu'à ajouter le mot générateur du syndrome a notre mot erroné pour trouver le mot de code original.
Sachant que nous pouvons corriger 2 erreurs, la table comporte tous les mots de 16 bits de poids=1 et de poids=2, ce qui fait
Cnp(16,1)+Cnp(16,2), soit 16+120=136 lignes. Cette table se présente dans la mémoire comme suit
|
Syndrome (8bits) |
Mot générateur (16bits) |
|
MatCtrl*0001h |
0001h |
|
MatCtrl*0002h |
0002h |
|
etc... |
etc... |
|
MatCtrl*8000h |
8000h (fin poids=1) |
|
MatCtrl*0003h |
0003h (début poids=2) |
|
MatCtrl*0005h |
0005h |
|
etc.. |
etc... |
|
MatCtrl*C000h |
C000h (fin poids=2) |
De cette façon nous pouvons corriger 2 erreurs. Le schéma global des méthodes d'encodage de décodage est le suivant :
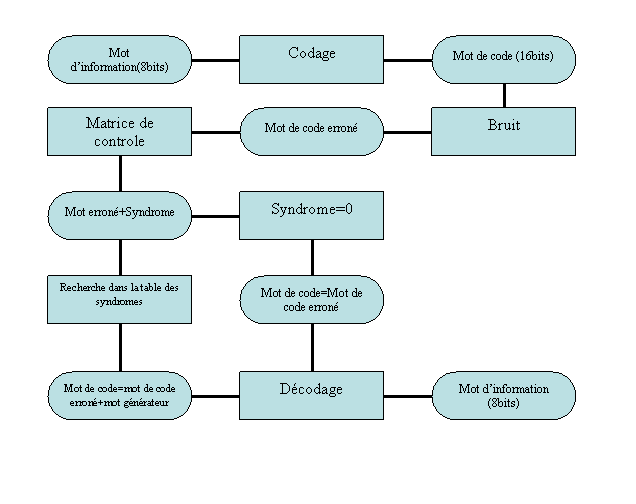
Image.
Traitement de l'image
Toute la partie graphique du projet a été réalisée a partir de fichier au format PCX. Nous avons appris comment sont organise les données compressées de ce type de fichier afin dans un premier temps afficher les images et ensuite de réaliser quelques effets détaillés par la suite. Mais avant toute chose il faut savoir comment se compose un fichier PCX.
Fichier PCX
Ce format a été développé au début des années 1980 par la société Zsoft Corporation. Ce format utilise la compression de type RLE (Run Length Encoding). Ce format d'image est un format palettisé, c'est a dire qu'à chaque octet de l'image correspond une couleur contenue dans une palette de couleurs. Chaque image possédant sa propre palette de couleurs, celle-ci sera stockée en fin de fichier.
Découpage d'un fichier PCX :
Un fichier PCX se découpe en trois parties :
La première constituée de 128 octets correspond a l'entête du ficher, on y trouve des informations diverses comme par exemple la version PCX utilisée pour encoder l'image.
Ensuite on trouve les octets de l'image crypte suivant le mode RLE décrit plus bas. Théoriquement la taille en mémoire de ces données varie en 10Ko et 128Ko
La fin du fichier contient la palette de l'image, elle occupe les 768 derniers octets du fichier. Une couleur Étant codée a l'aide de 3 octets (variant entre 0 et 255), précisant respectivement les proportions de rouge, vert et bleu, et l'image possédant 256 couleurs on retrouve bien les 768 octets.
Le principe du cryptage RLE, est de compresse les répétitions d'un même pixel afin d'éliminer certaines redondance de l'information: un premier octet indique le nombre de caractère a copier, et le second le caractère a copier.
Exemple :
|
10 10 10 10 10 |
est code 05 10 |
|
0A 0A 0A 0A 0A 0A 0A 0A 0A 0A |
est code 0A 0A |
Le codage d'un octet est réalisé selon ce schéma ; seulement par convention un octet sera répété uniquement si la valeur de l'octet précèdent est supérieure a C0h. Dans ce cas l'octet est répété autant de fois que la valeur cet octet moins C0h.
Si l'octet précèdent est inférieur a C0h, il est représenté directement la valeur de la couleur et l'octet actuel est compare a son tour a la valeur C0h.
Exemple :
|
10 C0 |
est code 10 C0 |
|
0A 0A 0A 0A 0A 0A 0A 0A 0A 0A |
est code CA 0A |
|
C1 |
est code C1 C1 |
Algorithme de décompression du fichier :
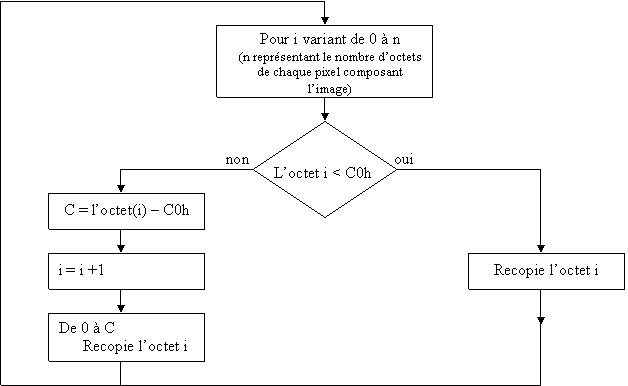
Pour exploiter l'image la fonction " LireFichier ", réalisée a partir de cet algorithme, décompresse l'image est stocke tout les pixels dans un Buffer prévu a cet effet. La palette de l'image est ensuite parcourue et a son tour sauvegardée.
La palette
Chaque couleur est renseignée par 3 octets représentant la proportion de vert, de rouge, et de bleu, soit 3 x 256 = 768 octets. La palette est toujours codée en fin de fichier a la suite des données de l'image. Sous le format PCX la palette de couleur n'est pas compressée, il est possible de la visualiser la directement a l'aide d'un éditeur hexadécimal
Mode graphique
Nous avons choisis d'utiliser le mode graphique " 13 ", car il est simple d'utilisation et donc très connu. Il permet de visualiser des images au format 320 x 200 palettisées en 256 couleurs, nous avons donc choisis les images correspondant a ces exigences.
Lorsque que le mode graphique 13 est actif les octets situes dans la RAM vidéo EGA/VGA représenté chacun des pixels de l'image. Ce buffer dans la RAM est toujours situe a l'adresse A000h (l'octet A000h : 0000 constituant le premier pixel en haut a gauche et l'octet A000 : FA00 le dernier pixel en bas a droite). Le chargement d'une palette se fait par l'intermédiaire des adresses 03C8h et 03C9h. Lors de l'envoie d'un numéro entre 0 et 255 (correspondant au futur numéro d'une couleur) sur l'adresse 03C8h, il suffit d'envoyer a l'adresse 03C9h les 3 octets correspondant aux composantes, dans l'ordre, de rouge, de vert et de bleu pour stocker une couleur dans la palette de la sortie VGA.
Algorithme de chargement de la palette :
Pour i de 0 a 255
Envoie i sur la sortie 03C8h
Pour j de 0 a 3
Lire l'octet (3 * i) + j
Envoie de (l'octet / 4) sur la sortie 03C9h
Fin pour
Fin pour
Remarque :
Attention, dans le format PCX les composantes (R,V,B) des couleurs de la palette sont des entiers compris entre 0 et 255 or la palette de couleur de la sortie VGA ne peut recevoir que des entiers compris entre 0 et 63 il suffit de diviser chaque composante extraite du fichier PCX par 4 pour que les couleurs soient correctement transmises. En faite dans certain mode graphique il y a la possibilité d'exploiter plusieurs niveaux de RGB pour chaque couleur. Dans le cas de l'utilisation du buffer EGA/VGA on a distingue 4 niveaux pour chaque couleur
Le premier niveau de couleur est code entre les valeurs 0 et 63
Le second entre 64 et 127
Le troisième entre 128 et 254
Le quatrième entre 193 et 254
Effets réalisés :
Dans toutes ces fonctions de rendu il a fallut intégrer des fonctions d'attente car sans celle-ci les effets se seraient réalisés beaucoup trop rapidement par l'ordinateur malgré le grand nombre de calculs a effectuer.
Ces fonctions se réalisent par des algorithmes très simples, les problèmes se posent lors de l'implémentation de ces fonctions en assembleur.
Fondu :
La fonction FadeTo permet de réaliser un fondu de l'image vers le noir ou le blanc et vise versa. Pour rendre un tel effet il suffit simplement de modifier toutes les couleurs de la palette de l'image progressivement et simultanément de façon a assombrir ou éclairer peu a peu toute l'image.
Effet d'écoulement :
Les fonctions EcouleIn et EcouleOut introduisent ou efface une image en la faisant défiler chacune des lignes de l'image sur l'écran, ce qui réalise un empilement ou un depilement de ces lignes en laissant une trace. Il suffit de recopier la ligne n sur la ligne n+1 et ainsi de suite jusqu'à la dernière ligne de l'écran
Exemple de réalisation du programme :
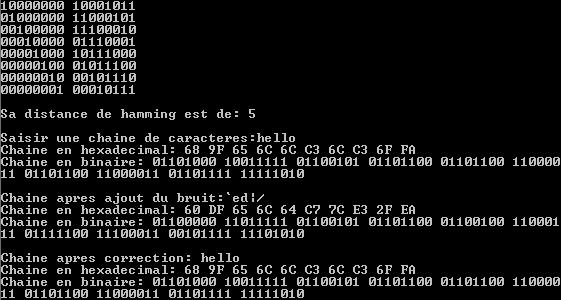
Tout d'abord un exemple de décodage d'une chaîne de caractères a saisir :
Dans un premier temps l'utilisateur entre une chaîne de caractère
Ensuite la chaîne est bruitée par l'ajout de 0 ou 1 de chaque caractère ascii.
Et enfin la chaîne est décodée par le code correcteur d'erreur
On constate que pour chaque caractère le code suivi de son code correcteur est afficher en hexadécimal et en binaire
L'algorithme est ensuite applique a une image (ici c'est une photo récupérée par le satellite Hubble)

L'image est ensuite bruitée comme dans le cas d'une transmission entre le télescope un laboratoire d'études
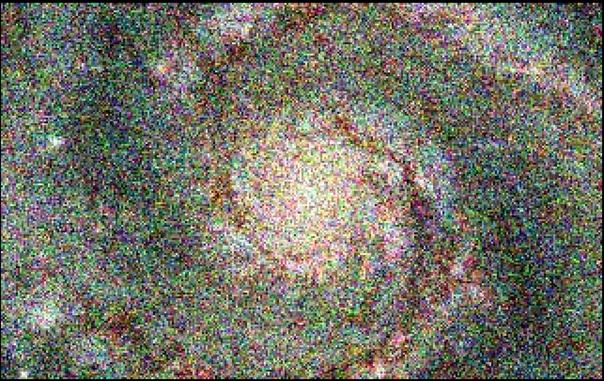
Et enfin re-décodée
Conclusion
La réalisation de ce projet nous a prit énormément de temps, car d'une part nous avons utilise un code correcteur différent du code de Hamming et d'autre part programmer le projet en assembleur. Cependant en partant des connaissances que nous avons acquit a l'UTBM nous avons recherche sur Internet les informations qu'il nous manquait a la réalisation du projet. Nous conclurons ce rapport en disant que ce projet nous a fortement intéressé ; en prenant pour preuve le fais que nous avons pris certaines " libertés " pour le rendre plus complet.